
Discourse Connectors Pada Peringkasan Dokumen Berbahasa Indonesia
DOI:
https://doi.org/10.21067/smartics.v7i1.5046Kata Kunci:
discourse connector, dokumen, kalimat, ringkasanAbstrak
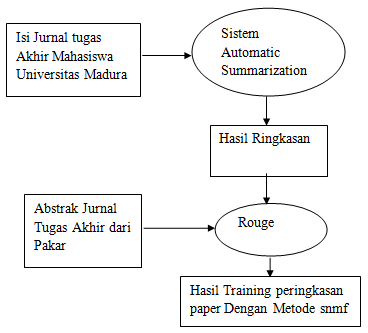
Dokumen yang memiliki isi sangat banyak akan menyulitkan bagi pembaca untuk menemukan intisari atau topik-topik dalam sebuah dokumen. Oleh sebab itu dibutuhkan sistem yang dapat meringkas dokumen untuk menemukan topik yang dibicarakan oleh dokumen tersebut. Dalam penelitian dokumen yang digunakan sebagai bahan ujicoba adalah paper skipsi mahasiswa S-1 informatika di Universitas Madura Pamekasan. Berbagai macam metode telah diterapkan dalam meringkas sebuah dokumen diantaranya menggunakan cosinus similarity untuk menentukan bobot serta keterhubungan antar kalimat yang satu dengan kalimat yang lain kemudian membuang kalimat-kalimat yang memiliki bobot yang kecil berdasarkan nilai threshold dari user. Bila panjang sebuah kalimat memiliki bobot kecil belum tentu kalimat tersebut tidak penting ketika berhubungan dengan kalimat yang lain. Oleh sebab itu dibutuhkan discourse connector sebagai penghubung dari kalimat yang satu dengan kalimat yang lain kemudian diberikan bobot tersendiri sesuai rumus discourse connector tersebut. Pada penelitian ini diharapkan dalam meringkas dokumen memiliki nilai akurasi yang lebih baik dari pada sebelumnya yaitu dibuktikan dengan f-measure yang tinggi lebih dari 70%
Referensi
[2] Ailin Li, Tao Jiang, Qingshuai Wang, Hongzhi Yu (2016), “The Mixture of TextRank and LexRank Techniques of Single Document Automatic Summarization Research in Tibenâ€Â, Journal of International Conference on Intelligent Human-Machine Systems and Cybernetics, IEEE (2016) hal. 514-519.
[3] Alex Alifimoff, “Abstraktive sentence Summarization with Attentive Deep RecurrentNeural Networks,†Journal of stanford, (2015)
[4] Anonymous, 2015. The Rouge Resource Network. [Online] Available at:http://rxnlp.com/rouge-2-0 [Accessed 21 Mei 2019].
[5] Anyman El-Kilany,Iman Saleh (2012), “Unsupervised Document Summarization Using Clusters of Dependency Graph Nodesâ€Â, Journal of International Conference on Intelligent Systems Design and Applications (ISDA), IEEE (2012),hal557-561.
[6] Anonymous, 2015. The Rouge Resource Network. [Online] Available at:https://github.com/ nmfpack/code/nmfsc.m [Accessed 22Januari 2018].
[7] Asian J. (2007) “Effective Techniques for Indonesian Text Retrievalâ€Â. PhD thesis School of Computer Science and Information Technology RMIT University Australia.
[8] Asian, J., Williams, H. E., & Tahaghoghi, S. M. M. (2005). Stemming Indonesian. In Conferences in Research and Practice in Information Technology Series, Vol. 38, Hal. 307–314.
[9] Babuska, R. (2009). Fuzzy and Neural Control. Netherlands: Delft University of Technology. Daniel D. Lee dan H. Sebastian Seung,Algorithms for Non-negative Matrix Factorization
[10] Jyoti Bora, D. dan Anil Kumar Gupta. (2014) . A Comparative Study Between Fuzzy Clustering Algorithm and Hard Clustering Algorithm dalam
Unduhan
Diterbitkan
Cara Mengutip
Terbitan
Bagian
Lisensi

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.



